|
I am a member of technical staff (research scientist) at OpenAI. Previously, I was a postdoctoral researcher at the Stanford NLP group, supervised by Prof. Christopher Manning and Prof. Christopher Potts. Previously I did my PhD at the Swiss AI lab IDSIA, working with Prof. Jürgen Schmidhuber. I work on compositionality and systematic generalization, with the goal of improving the reasoning capabilities, trustworthiness, and data efficiency of neural models. My goal is to shift the preference of neural networks to learn general, soft algorithms when possible, instead of relying on fuzzy memorization of seen patterns. Instead of relying on symbolic systems, I want to bias the networks to learn rules implicitly, without explicit supervision, with minimal hardcoded structure, and without reducing their expressivity. I am also interested in mechanistic interpretability, which can provide a deep understanding of how the models work and the bottlenecks causing the networks to fail in composition and generalization. I consider the lack of compositionality and systematic generation to be the main obstacle to a more generally applicable artificial intelligence. During the summer of 2022, I did an internship at DeepMind. Before starting my PhD, I received a master's degree from Budapest University of Technology and Economics and worked as a research scientist at AImotive on developing self driving cars. |

|
|
|

|
Houjun Liu, Shikhar Murty, Christopher D. Manning, Róbert Csordás Preprint, 2025 pdf / code / bib We propose an unsupervised method for parallel thinking in latent space, by learning to fork residual streams in the Transformer. |

|
Anand Gopalakrishnan, Róbert Csordás, Jürgen Schmidhuber, Michael C. Mozer Preprint, 2025 pdf / bib We propose a new, complex positional encoding that outperforms RoPE and generalizes better to longer sequences. |

|
Róbert Csordás, Christopher D. Manning, Christopher Potts NeurIPS, 2025 pdf / code / Colab demo / bib We analyze the residual stream of LLMs and show that they are not using their depth efficiently, they are unlikely to be compositional, and deeper models spread out identical computations to the shallower ones. |
|
Piotr Piękos, Róbert Csordás, Jürgen Schmidhuber Preprint, 2025 pdf / bib We introduce MoSA, a new sparse attention mechanism using dynamic, learned content-based sparsity. We show that MoSA can be used for acceleration, KV cache reduction, or scaling the attention to more attention heads, improving performance. |

|
Vincent Herrmann, Róbert Csordás, Jürgen Schmidhuber International Conference on Machine Learning (ICML), 2025 pdf / bib We propose the prediction of the model's future hidden states as a new way to measure the "interestingness" of the model's internal computation. |

|
Julie Kallini, Shikhar Murty, Christopher D. Manning, Christopher Potts, Róbert Csordás International Conference on Learning Representations (ICLR), 2025 pdf / code / bib We propose a dynamic token deletion mechanism that forces merging information from early layers of the encoder of ByT5, speeding it up significantly. |

|
Róbert Csordás, Christopher Potts, Christopher D. Manning, Atticus Geiger BlackboxNLP 2024 pdf / code / bib We show that RNNs, under certain conditions, prefer to store sequences in a magnitude-based encoding that violates the Linear Representation Hypothesis (LRH). This counterexample strongly indicates that interpretability research should not be confined by the LRH. |

|
Róbert Csordás, Kazuki Irie, Jürgen Schmidhuber, Christopher Potts, Christopher D. Manning NeurIPS 2024 pdf / code / training code / checkpoints / bib We propose a novel Mixture-of-Experts Universal Transformer using σ-MoE, SwitchHead, layer grouping, and a novel peri-layernorm. Our method slightly outperforms standard Transformers on language modeling and zero-shot downstream tasks with less compute and memory requirements. |

|
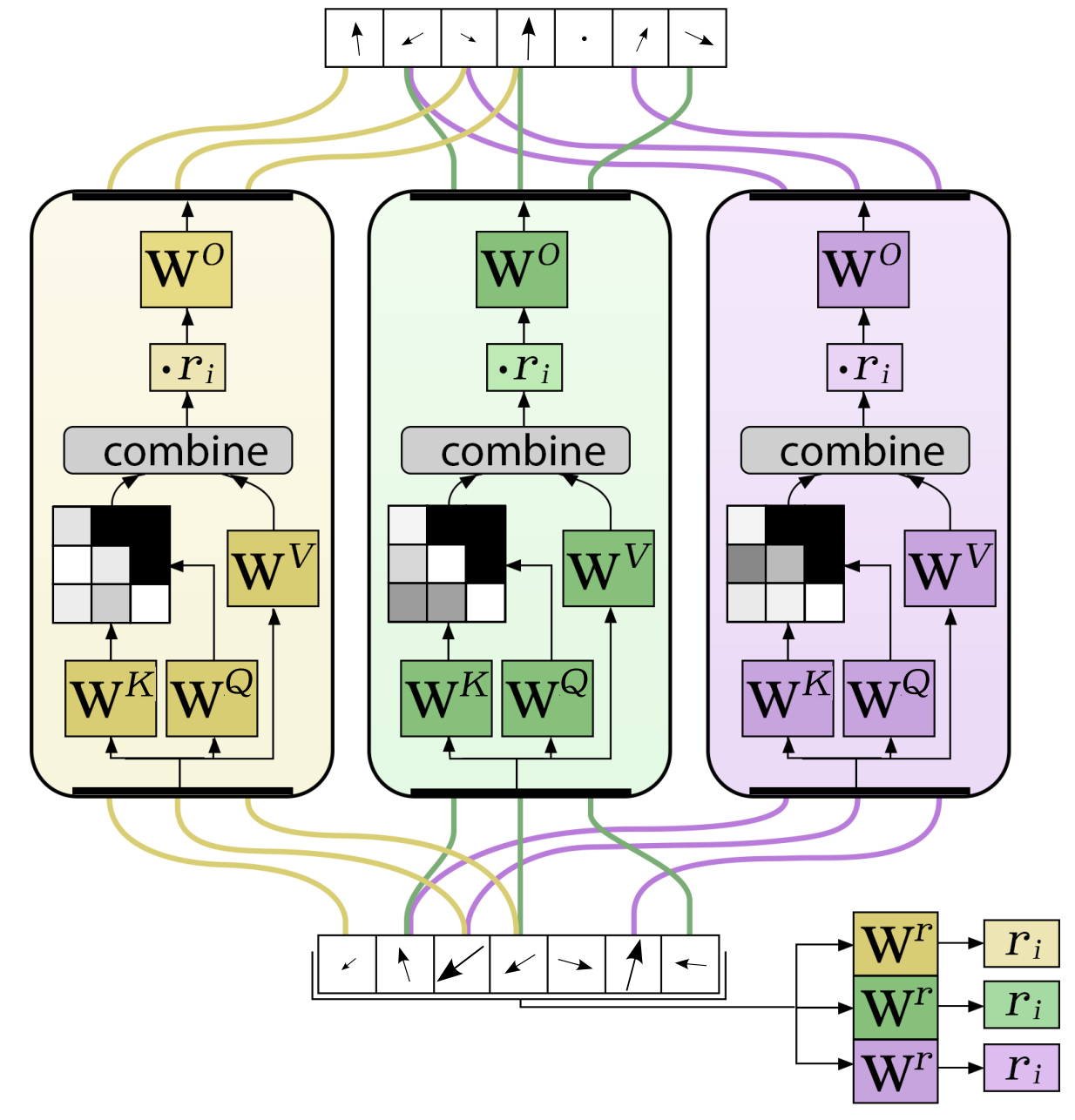
Róbert Csordás, Piotr Piękos, Kazuki Irie, Jürgen Schmidhuber NeurIPS 2024 pdf / code / training code / bib We propose a novel MoE attention, which can match the performance of parameter-matched dense models with a fraction of the compute and memory requirements. We also present the "SwitchAll" model, where each layer is an MoE. |
|
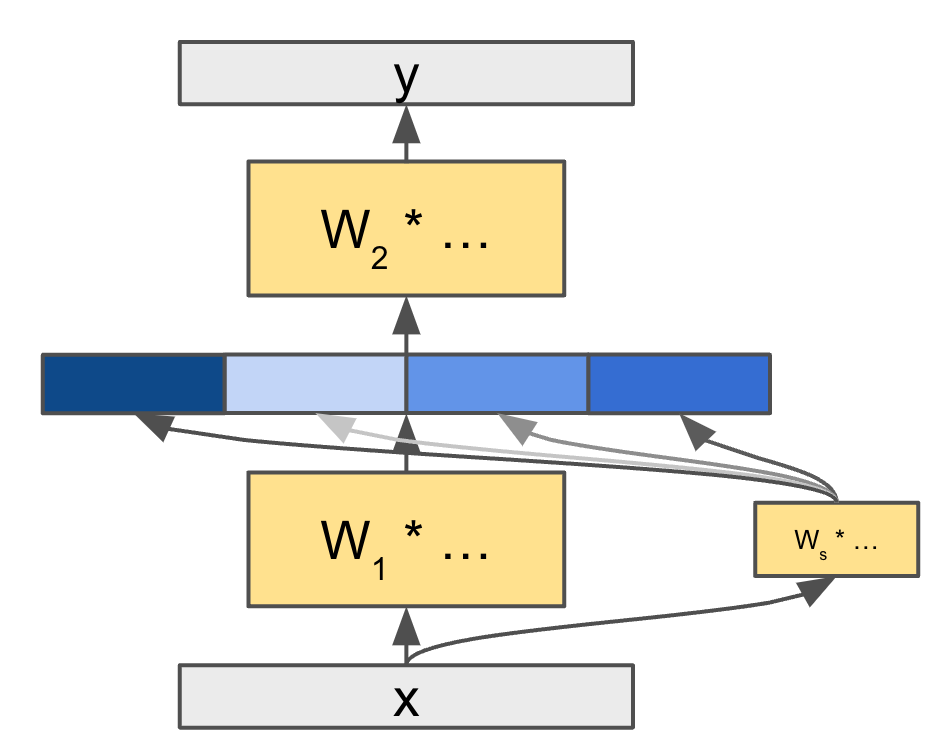
Róbert Csordás, Kazuki Irie, Jürgen Schmidhuber EMNLP Findings 2023 pdf / code / bib We present different approximation methods for two-layer feedforward networks in a unified framework. Based on this, we develop a better-performing MoE, which matches or even outperforms the parameter-equivalent dense models. |

|
Kazuki Irie*, Róbert Csordás*, Jürgen Schmidhuber International Conference on Artificial Neural Networks (ICANN), 2024 pdf / code / bib We show that vector quantization is a special case of self-organizing maps (SOMs). Using the SOM formulation proposed by Kohonen in his 1982 paper improves converge speed, makes the training more robust, and results in a topologically organized representation space. |
|
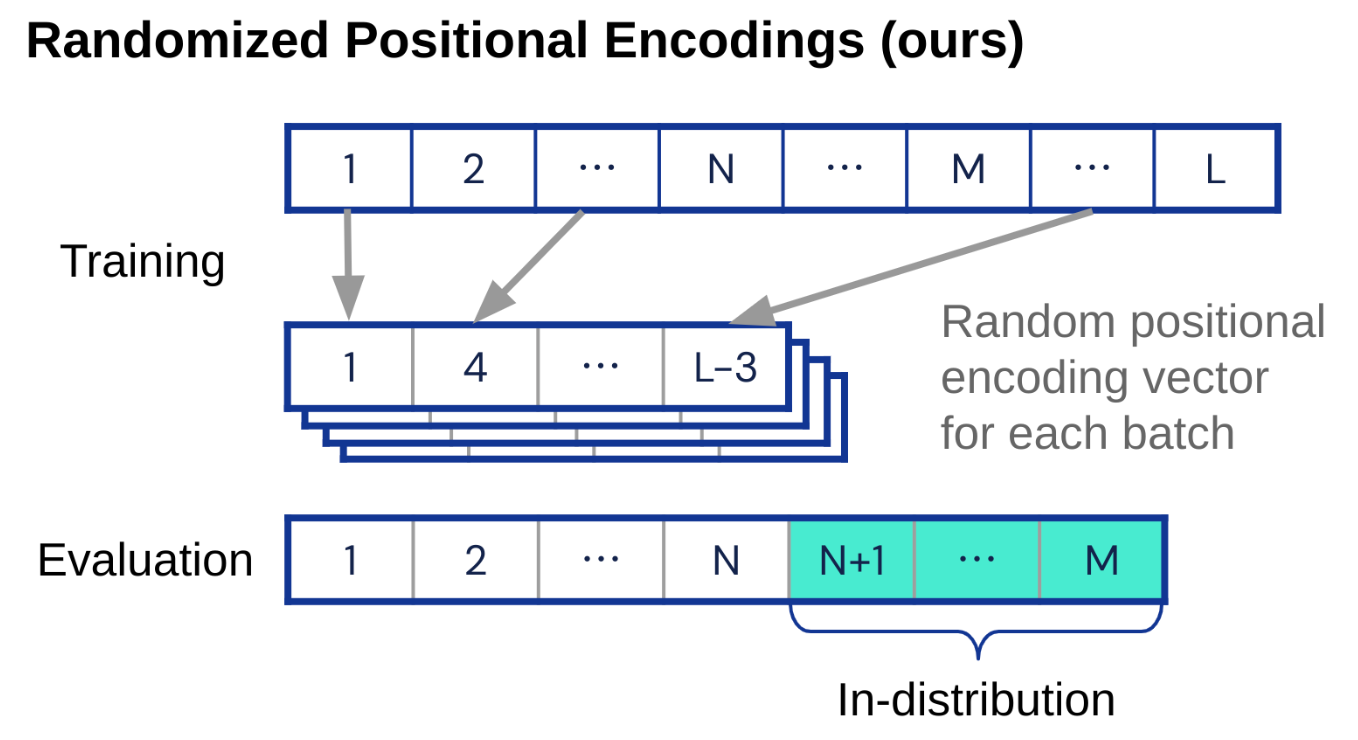
Anian Ruoss, Gregoire Deletang, Tim Genewein, Jordi Grau-Moya, Róbert Csordás, Mehdi Bennani, Shane Legg, Joel Veness Annual Meeting of the Association for Computational Linguistics (ACL), 2023 pdf / bib We show that the transformer's poor length generalization is linked to the positional encodings being out-of-distribution. We introduce a novel positional encoding that samples a randomized ordered subset of sinusoidal positional encodings. We show the befit of this positional encoding on various algorithmic tasks. |

|
Róbert Csordás, Kazuki Irie, Jürgen Schmidhuber Empirical Methods in Natural Language Processing (EMNLP), 2022 pdf / code / poster / bib We developed a new dataset for testing systematicity based on CTL by partitioning the data based on functional groups. Using this, we were able to show that Transformers naturally learn multiple, incompatible representations of the same symbol. As a result, the network fails when the symbol is fed to a function that has not seen that specific representation before. |

|
Borja Ibarz, Vitaly Kurin, George Papamakarios, Kyriacos Nikiforou, Mehdi Bennani, Róbert Csordás, Andrew Dudzik, Matko Bošnjak, Alex Vitvitskyi, Yulia Rubanova, Andreea Deac, Beatrice Bevilacqua, Yaroslav Ganin, Charles Blundell, Petar Veličković Learning on Graphs (LoG), 2022 pdf / code / bib We train multi-task generalist reasoning architecture on the CLRS algorithmic reasoning benchmark that shares a single, universal processor among all tasks. Furthermore, we introduce numerous improvements to the previous best architecture, achieving new SOTA even in the single-task case. |

|
Kazuki Irie*, Róbert Csordás*, Jürgen Schmidhuber International Conference on Machine Learning (ICML), 2022 pdf / code / bib Linear layers in neural networks (NNs) trained by gradient descent can be expressed as a key-value memory system which stores all training datapoints and the initial weights, and produces outputs using unnormalised dot attention over the entire training experience. While this has been technically known since the ’60s, no prior work has effectively studied the operations of NNs in such a form. We conduct experiments on this dual formulation and study the potential of directly visualising how an NN makes use of training patterns at test time, as well as its limitations. |

|
Kazuki Irie, Imanol Schlag, Róbert Csordás, Jürgen Schmidhuber International Conference on Machine Learning (ICML), 2022 pdf / code / bib The weight matrix (WM) of a neural network (NN) is its program which remains fixed after training. The WM or program of a self-referential NN, however, can keep rapidly modifying all of itself during runtime. In principle, such NNs are capable of recursive self-improvement. Here we propose a scalable self-referential WM (SRWM) that uses self-generated training patterns, outer products and the delta update rule to modify itself. |

|
Róbert Csordás, Kazuki Irie, Jürgen Schmidhuber International Conference on Learning Representations (ICLR), 2022 pdf / code / slides / poster / bib We look at Transformers as a system for routing relevant information to the right node/operation at the right time in the grid represented by its column. To facilitate learning useful control flow, we propose two modifications to the Transformer architecture: copy gate and geometric attention. The resulting Neural Data Router (NDR) architecture achieves length generalization compositional table lookup task, as well as generalization across computational depth on the simple arithmetic task and ListOps. |

|
Róbert Csordás, Kazuki Irie, Jürgen Schmidhuber Empirical Methods in Natural Language Processing (EMNLP), 2021 pdf / code / slides / poster / bib We improve the systematic generalization of Transformers on SCAN (0 -> 100% with length cutoff=26), CFQ (66 -> 81% on output length split), PCFG (50 -> 85% on productivity split, 72 -> 96% on systematicity split), COGS (35 -> 81%), and Mathematics dataset, by revisiting model configurations as basic as scaling of embeddings, early stopping, relative positional embedding, and weight sharing. We also show that relative positional embeddings largely mitigate the EOS decision problem. Importantly, differences between these models are typically invisible on the IID data split, which calls for proper generalization validation sets. |

|
Kazuki Irie, Imanol Schlag, Róbert Csordás, Jürgen Schmidhuber Conference on Neural Information Processing Systems (NeurIPS), 2021 pdf / code / bib Inspired by the effectiveness of Fast Weight Programmers in the context of Linear Transformers, in this work we explore the recurrent Fast Weight Programmers (FWPs), which exhibit advantageous properties of both Transformers and RNNs. |

|
Róbert Csordás, Sjoerd van Steenkiste, Jürgen Schmidhuber International Conference on Learning Representations (ICLR), 2021 pdf / code / slides / poster / bib This paper presents a novel method based on learning binary weight masks to identify individual weights and subnets responsible for specific functions. We contribute an extensive study of emerging modularity in NNs that covers several standard architectures and datasets using this powerful tool. We demonstrate how common NNs fail to reuse submodules and offer new insights into systematic generalization on language tasks. |
|
Kazuki Irie, Imanol Schlag, Róbert Csordás, Jürgen Schmidhuber NeurIPS DistShift Workshop, 2021 pdf / code We present our critical observations on the iWildCam and FMoW datasets of the recently released WILDS benchmark. We show that (1) Conducting separate cross-validation for each evaluation metric is crucial for both datasets, (2) A weak correlation between validation and test performance might make model development difficult for iWildCam, (3) Minor changes in the training of hyper-parameters improve the baseline by a relatively large margin, (4) There is a strong correlation between certain domains and certain target labels. |

|
Róbert Csordás, Jürgen Schmidhuber International Conference on Learning Representations (ICLR), 2019 NeurIPS Workshop on Relational Representation Learning, 2018 pdf / code / slides / poster / bib We propose three improvements for the DNC architecture, which significantly improves its performance on algorithmic reasoning tasks. First, the lack of key-value separation makes the address distribution dependent also on the stored value. Second, DNC leaves deallocated data in the memory, which results in aliasing. Third, the temporal linkage matrix quickly degrades the sharpness of the address distribution. Our proposed fixes improve the mean error rate on the bAbI question answering dataset by 43%. |
|
|
|
NeurIPS 2024 We organize a one-day workshop that focuses on improving reasoning in neural networks, particularly the challenges and strategies for achieving System-2 reasoning in transformer-like models. The workshop addresses issues like distinguishing memorization from rule-based learning, understanding, syntactic generalization, and compositionality. |
|
|
|
Róbert Csordás, Ágnes Kis-Benedek, Balázs Szalkai US Patent 10,380,753 We propose a fast and accurate method for generating displacement maps from stereo image pairs using neural networks. This enables more robust depth prediction compared to standard methods. |
|